



Was ist dbt und warum sollte man sich damit beschäftigen?
dbt (data build tool) ist ein Open Source Framework für Transformationen, mit dem sich Daten im Data Warehouse mithilfe modular geschriebener SQL Anweisungen transformieren lassen. Dank seiner schlanken, dateibasierten Architektur bringt es Methoden der Softwareentwicklung in Analyse Workflows ein.
Alles, was zu den Daten gehört außer dem eigentlichen Dateninhalt, liegt in versionierten und modularen SQL und YAML Dateien. Da es sich ausschließlich um reinen Text handelt, eignet sich dieses Format von Natur aus für Versionskontrolle, zum Beispiel mit GitHub. Die Zusammenarbeit im Projekt wird dadurch einfacher und Änderungen bleiben transparent. Pull Requests, Code Reviews, Branching, CI/CD und Tests, also all die Praktiken, die Softwareentwicklung verlässlich gemacht haben, lassen sich so auch auf Datenpipelines anwenden und bringen Struktur in komplexe Datenlandschaften.
Der Datenfluss in dbt – von Rohdaten zu fachlich nutzbaren Daten
Ein typisches Konzept im Data Engineering ist ein Drei-Schichten-Modell, das den Verarbeitungsgrad von Daten beschreibt. Es reicht von Rohdaten über Zwischenschritte bis hin zu Daten, die fachlich nutzbar sind und in der Regel bereits angereichert und aggregiert wurden. Für dieses dreiteilige Konzept gibt es verschiedene Bezeichnungen. Ein bekanntes Beispiel ist die Medallion Architektur, bei der die Schichten Bronze, Silber und Gold heißen.
| Medallion | dbt Äquivalent | Beschreibung |
|---|---|---|
| Bronze | Sources (_sources.yml) |
Rohdaten Tabellen, unverändert aus dem Quellsystem |
| Silver | staging/ + intermediate/ |
Bereinigt, dedupliziert, typisiert und standardisiert |
| Gold | marts/ |
Analysefertige, aggregierte Daten |
Auf diese Weise werden Daten an verschiedenen Stellen der Pipeline materialisiert. Das erleichtert Wartung und Fehlersuche und schafft Nachvollziehbarkeit. Auch in dbt fließen die Daten von roh zu verarbeitet und durchlaufen dabei mehrere Transformationsschritte.
Im DAG von dbt, also im gerichteten azyklischen Graphen, lässt sich visuell nachvollziehen, wie Daten durch die einzelnen Modelle fließen und von welchen vorgelagerten Modellen sie abhängen. Wer bereits mit Orchestrierungstools wie Airflow gearbeitet hat, wird dieses Konzept wiedererkennen:
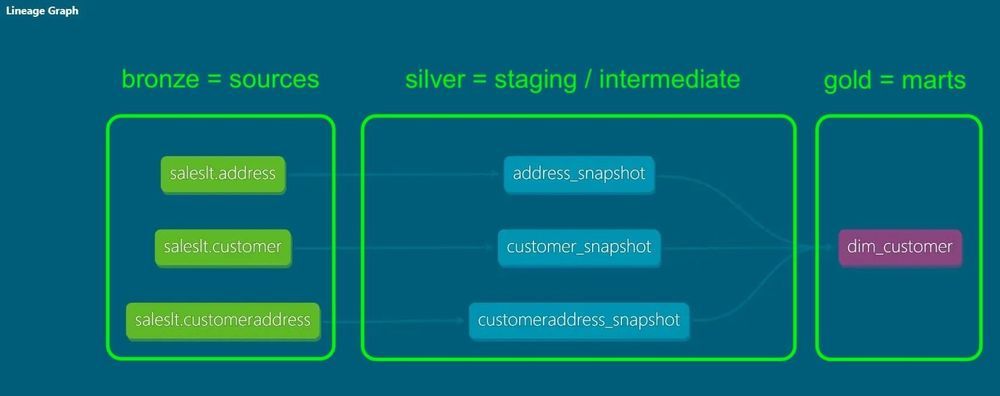
Ein minimalistisches dbt Projekt
In einem dbt Projekt werden Daten transformiert, während sie durch verschiedene Modelle fließen. Wenn in dbt alles dateibasiert ist, welche Dateien braucht ein dbt Projekt mindestens, um zu funktionieren?
Grundsätzlich enthalten SQL oder Python Dateien die Modelle, zum Beispiel SELECT Statements oder pandas DataFrames. Konfiguration und Dokumentation liegen in .yml Dateien. Unten ist ein minimales, aber funktionsfähiges Setup zu sehen. Besonders wichtig ist die unverzichtbare Datei dbt_project.yml, die die zentrale Projektkonfiguration enthält:
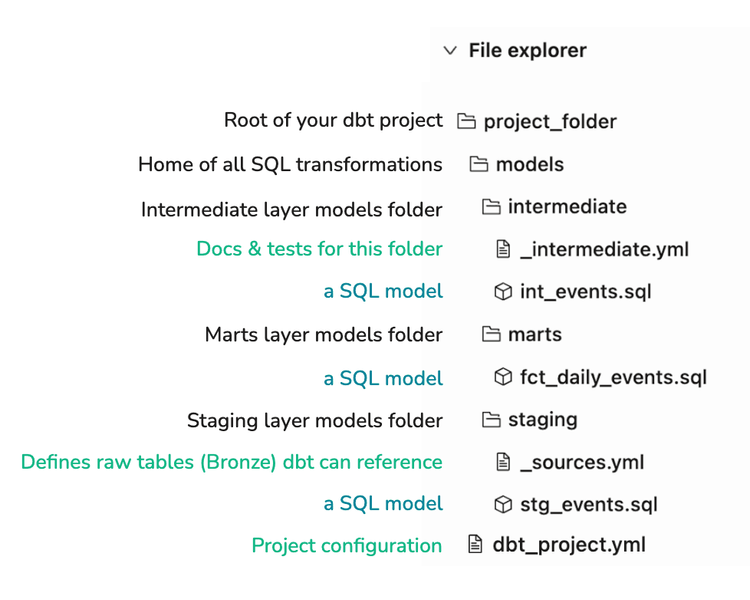
Tipp: Wenn dein dbt Projekt Teil eines größeren Repositories ist, zum Beispiel neben Ingestion Skripten oder Orchestrierungscode, empfiehlt es sich, es in einem Unterverzeichnis wie transform/ oder dbt/ abzulegen. So bleibt die Struktur übersichtlich.
Benennungskonventionen in dbt
Bei dbt dreht sich alles um Modularität. Transformationen werden einmal definiert und im weiteren Verlauf des Datenflusses wiederverwendet. Es gibt einige hilfreiche Konventionen, mit denen sich bereits am Dateinamen erkennen lässt, worum es sich handelt. Das hilft auch dabei, sich in verschachtelten Repository Strukturen besser zurechtzufinden.
| Präfix | Schicht | Beispiel |
|---|---|---|
| stg_ | Staging | stg_saleslt__customers.sql |
| int_ | Intermediate | int_customers_enriched.sql |
| fct_ | Marts (facts) | fct_daily_orders.sql |
| dim_ | Marts (dimensions) | dim_customers.sql |
Außerdem trennt der doppelte Unterstrich __ das Quellsystem vom Namen der Entität. So werden Mehrdeutigkeiten vermieden. stg_google_analytics__campaigns ist eindeutig die Tabelle campaigns aus google_analytics und nicht analytics_campaigns aus google. Dateien mit einem führenden Unterstrich wie _sources.yml sind YAML Konfigurationsdateien und keine SQL Modelle. Sie erscheinen daher nicht im DAG.
Eine minimalistische dbt_project.yml Datei

Was die einzelnen Abschnitte bedeuten:
| Schlüssel | Bedeutung |
|---|---|
| name | Projektkennung, muss mit dem Eintrag unter models: übereinstimmen |
| profile | Verweist auf die Verbindungsstellen in ~/.dbt/profiles.yml |
| model-paths | Gibt an, wo dbt nach .sql Modellen sucht |
| +materialized | view= schnellere Builds;table = schnellere Abfragen |
Warum Staging gleich View ist, Marts aber als Table angelegt werden
• Staging Modelle sind Bausteine und werden in der Regel nicht direkt abgefragt. Views sparen daher Speicherplatz.
• Marts werden von Analystinnen und Analysten sowie von Dashboards abgefragt. Tabellen bieten hier meist die bessere Performance.
Und das ist im Grunde schon alles. Damit hast du alles, was du brauchst, um dbt build auszuführen und deinen ersten DAG zum Leben zu erwecken. Im nächsten Blog geht es darum, wie sich Tests, Dokumentation und Scheduling ergänzen lassen, damit dieses Setup produktionsreif wird.
Bereit für moderne Datenprozesse?
Ob wachsende Anforderungen, komplexe Datenflüsse oder der Wunsch nach mehr Transparenz und Wiederverwendbarkeit – Wir unterstützen Euch dabei, dbt so einzusetzen, dass daraus ein tragfähiges Fundament für moderne und skalierbare Datenprozesse entsteht. Lasst uns darüber sprechen, wie wir Euch bei Eurem dbt Vorhaben unterstützen können.
JETZT UNVERBINDLICHE BERATUNG ANFRAGEN →
Oder ruft uns einfach an: 040 2109 1818-0


