



Agents. Agents. Agents… aber bitte mit Mehrwert
Ja, man kann Agents einfach bauen. Sie sinnvoll nutzen ist leider viel schwieriger. Auf dem Snowflake Summit 2026 wurde dieses Thema intensiv diskutiert. Laut einem Bericht der RAND Corporation scheitern schätzungsweise mehr als 80 Prozent der AI Projekte. Eine ernüchternde Statistik, mit der Anbieter im Datenbereich besonders gerne um sich werfen, meistens genau in dem Moment, bevor sie Euch das Tool präsentieren, das Eure Strategie angeblich im Alleingang retten wird.
Wer sich jedoch auf dem Snowflake Summit 2026 im San Francisco Moscone Center umsah, kam um eine Frage nicht herum: Bewegt sich der Markt tatsächlich in Richtung dieser autonomen, agentenbasierten Zukunft, die in den Keynotes so lautstark angepriesen wird? Oder erleben wir hier lediglich die perfekt synchrone Kehrtwende globaler Marketingabteilungen? Realität in den Datenteams ist schließlich nach wie vor, dass sie in kaputten Pipelines, ungeprüften Dashboards und mühsamen Migrationen von Altsystemen versinken. Es liegt also nahe, bei diesem plötzlichen Ansturm auf „agentische“ Lösungen skeptisch zu sein und sich zu fragen, ob hier nicht einfach alte Probleme der Data Governance in ein frisches Gewand aus AI-Trendwörtern gehüllt werden.

Das eigentliche Nadelöhr ist der Kontext
Doch nehmen wir einmal an, der Markt entwickelt sich tatsächlich genau so, wie die Anbieter behaupten. Nehmen wir an, dass das Nadelöhr für AI im Unternehmen heute nicht mehr die reine Rechenleistung oder das Datenvolumen ist, sondern der Kontext.
Wenn wir diese Prämisse akzeptieren, ergibt die Grundstimmung der diesjährigen Keynotes und Fachvorträge auf dem Snowflake Summit 2026 plötzlich absolut Sinn. Die Botschaft wirkte weniger wie ein Schaulaufen neuer Produktfunktionen, sondern vielmehr wie eine fundamentale Neuausrichtung der gesamten Datenplattform. Wir bewegen uns weg von der Ära statischer Dashboards und starrer Datenpipelines, hin zu einer Ära von autonomen Agenten und direkten Aktionen. Um diesen Wandel zu meistern, dürfen Datenteams Daten nicht mehr nur stumpf speichern, sie müssen beginnen, deren Bedeutung explizit zu programmieren (Context Engineering).
Agenten scheitern an fehlender Bedeutung, nicht an Daten
Die Annahme, man müsse ein Large Language Model (LLM) lediglich auf ein riesiges Data Warehouse ansetzen, um automatisch geschäftlichen Mehrwert zu generieren, ist einer der häufigsten Denkfehler. Die Realität zeigt: AI-Agenten benötigen ein weitaus strikteres und verlässlicheres Fundament als menschliche Analysten. Menschen können Intuition nutzen, um Lücken in schlecht definierten Daten zu schließen; Agenten können das nicht.
Wenn ein Agent versucht, eine automatisierte Aktion auszuführen, führt ein Mangel an klarem Kontext unweigerlich zu Halluzinationen, fehlerhafter Logik und verletzten Compliance-Vorgaben. Ein Praxisbeispiel aus der Conversational-BI-Einführung von Siemens brachte dieses Kernproblem auf den Punkt:
„Dashboards are static, partial snapshots of a dynamic reality.“
(Dashboards sind statische, unvollständige Momentaufnahmen einer dynamischen Realität.)

Welche Grundlagen Unternehmen jetzt brauchen
Um den Schritt weg von Dashboards und hin zu sicherer, agentenbasierter Automatisierung zu gehen, benötigen Unternehmen:
•
Eine vertrauenswürgige semantische Ebene: Eine abstrahierte Geschäftsebene, die technische Datenstrukturen fehlerfrei in echte Business-Logik übersetzt.
•
Eine echte „Single Source of Truth“ (SSOT): Zentralisierte, unumstößliche Metriken-Definitionen, die über isolierte Anwendungen hinweg gelten.
•
Ein „Golden Set“ an Testfragen: Standardisierte Test-Suiten und Validierungs-Workflows, mit denen die Genauigkeit eines Agenten vor dem Release gemessen wird.
•
Eine verlässliche Governance: Ein Regelwerk, das den Datenzugriff zeilenbasiert, rollenbasiert und gegebenenfalls absichtsbasiert kontrolliert.
„Context Engineering“ wird zum entscheidenden neuen Jobprofil im Datenbereich
Da der Fokus immer stärker auf die Bereitstellung von Bedeutung rückt, wandelt sich die traditionelle Rolle des Datenanalysten. Die Branche bewegt sich weg vom reinen Erstellen und Warten von Diagrammen und Pipelines hin zu einer Disziplin namens Context Engineering. Das Wissen, dass Analysten das Erstellen und Warten verschiedener Inhalte ermöglicht, soll explizit gemacht werden.
In diesem neuen Paradigma bauen Datenexperten die „Bedeutungsschicht“, die sich wie eine Schutzhülle um die Datenbestände des Unternehmens legt. Erfolg wird nicht mehr daran gemessen, ob eine AI eine Textantwort ausspuckt, sondern ob ein Agent eine Aktion wiederholt, fehlerfrei und innerhalb sicherer Leitplanken autonom ausführen kann.
Das Partner-Ökosystem konzentriert sich auf die Zwischenschicht (Between Layer)
Beim Gang durch die Expo-Halle mit über 190 Partnern auf dem Snowflake Summit 2026 kristallisierte sich ein klares Architekturmuster heraus. Die moderne Tool-Landschaft formiert sich rasant um das Bindeglied, die Zwischenschicht, direkt zwischen den rohen Cloud-Warehouses und den nachgelagerten Anwendungen. Unabhängig von ihrer Nische verfolgten die Anbieter ein bemerkenswert einheitliches Ziel: Das zentralisierte Data Warehouse sowohl für Menschen als auch für autonome Agenten nutzbar zu machen, ohne absolutes Chaos zu stiften.

•
Semantik- & Kontext-Engines: Plattformen, die Definitionen konsolidieren, Logiken zentralisieren und die einheitliche Geschäftsbedeutung für nachgelagerte Tools bereitstellen.
•
Governance- & Vertrauens-Leitplanken: Tools, die sicherstellen, dass Agenten nur auf verifizierten Datenquellen operieren, oft gestützt durch Human-in-the-Loop-Workflows statt passiver Dokumentation.
•
Kosten- & Compute-Optimierer: Ausführungsschichten, die unvorhersehbare, von Agenten getriebene Abfragelasten intelligent und wirtschaftlich sinnvoll routen.
•
Managed High-Speed-Ingestion: Streaming-Alternativen in Echtzeit, die den Wartungsaufwand klassischer, starr gebauter ELT-Pipelines eliminieren wollen.
Was das konkret für Datenverantwortliche bedeutet
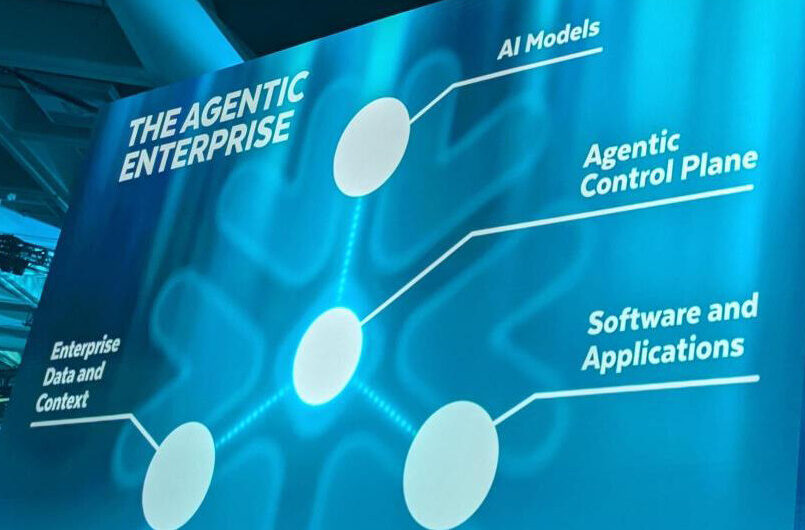
Die Roadmap von Snowflake verdeutlicht es: Die Plattform entwickelt sich vom reinen Datenlager zur agentischen Steuerebene (Agentic Control Plane), wie der CEO in der Keynote verkündete. Falls man die Vision des „Agentic Enterprise“ teilt, bedeutet das, dass man sich jetzt ein paar sehr konkrete Fragen stellen muss:
1. Wo liegt Euer Geschäftskontext?
Wo ist Euer Geschäftskontext aktuell dokumentiert? Liegt er sauber definiert in einer zentralen semantischen Schicht, oder ist er verstreut über die Köpfe Eurer Analyst:innen, in den SQL-Skripten von fünf verschiedenen BI-Tools und in veralteten Confluence-Seiten?
2. Ist dieser Kontext maschinenlesbar?
Wie zugänglich ist dieser Kontext für eine Maschine? Wenn Ihr heute einen AI-Agenten auf Eure Daten ansetzt: Kann er den Unterschied zwischen „Umsatz brutto“ und „Umsatz netto“ anhand Eurer Systemmetadaten fehlerfrei erkennen, oder wird er halluzinieren, weil die Definitionen implizit sind?
3. Wie testet Ihr die Wahrheit?
Habt Ihr ein automatisiertes Testverfahren, ein „Golden Set“ an geschäftskritischen Fragen, mit dem Ihr bei jeder Änderung an der Datenpipeline sofort prüfen können, ob die AI noch die richtigen Antworten liefert?

Fazit vom Snowflake Summit 2026: Der Wettbewerbsvorteil liegt im Kontext
Die Zukunft der Analytics liegt nicht in einem optisch noch schöneren Dashboard. Sie liegt in einem robusten, deterministischen Vertrag zwischen Euren Daten und Euren Geschäftsentscheidungen. Dieser Vertrag wird durch Kontext geschrieben, durch semantische Modelle, eiserne Governance und kontinuierliche, automatisierte Tests, nicht durch Ad-hoc-SQL oder zerbrechliche Benutzeroberflächen.
Die Gewinner der kommenden Jahre werden nicht die Unternehmen mit den schicksten Chatbots sein. Es werden die Organisationen sein, die ihren Geschäftskontext so sauber aufbereitet haben, dass Agenten und Menschen darauf basierend sicher, vorhersehbar und wiederholbar fundierte Aktionen ausführen können.


