Im letzten Beitrag, Ein föderiertes Data Warehouse: Skalierbare Multi-Mandanten-Architektur mit Automation & Templates, ging es um den Aufbau eines föderierten Data Warehouse und darum, wie wir für ein großes Unternehmen und dessen Betriebe die Daten aus diversen Quellen nutzbar machen, damit sie mittels einer Dashboard-Suite ihre Medienkampagnen gut steuern können.
Das Unternehmen ist in mehrere Betriebe aufgeteilt. Jeder Betrieb betreibt eigene Kampagnen auf unterschiedlichen Kanälen. Fast alle Kanäle (wie z. B. TikTok) werden von mehr als einem Betrieb mit jeweils eigenen Accounts bespielt.
Der Fokus lag im oben verlinkten Beitrag vor allem auf der Transformation innerhalb des föderierten Data Warehouse. In diesem Beitrag geht es darum, wie die Rohdaten überhaupt in das System gelangen. Wir haben zwei Arten von Daten:
• Manuell gepflegte Daten
• Daten aus anderen Systemen
Manuell gepflegte Daten
Manuelle Datenpflege an sich ist zwar organisatorisch anspruchsvoll, technisch jedoch recht geradlinig.
Wir haben eine App geschrieben, die XLSX- und CSV-Dateien annimmt und auch die manuelle Dateneingabe ermöglicht. Die so bereitgestellten Daten werden zusammen mit Metadaten an eine Tabelle im Data Warehouse angehängt.
Eine spätere Transformation filtert die nicht mehr relevanten Zeilen aus.
Der Sinn dieser Append-only-Strategie besteht darin, dass ältere Versionen der Daten nicht verloren gehen. Es kann nachverfolgt werden, wann etwas hochgeladen wurde und von wem. Diese Struktur ermöglicht Auditing und einfache Rollbacks.
Daten aus anderen Systemen
Komplexer ist die Anbindung externer Datenquellen wie Social-Media-Plattformen und Web-Analytics. Hier hat jeder Anbieter eigene Schnittstellen und Prinzipien.
Eine Eigenentwicklung wäre hier zu teuer. Deshalb haben wir nach einem Anbieter gesucht, der sowohl die meisten der Datenquellen anbinden kann als auch die regulatorischen Anforderungen unserer Kundin erfüllt. Unsere Wahl fiel auf Adverity.
Adverity bietet eine Web-UI, in der wir Data Streams anlegen können. Für jeden Social-Media-Channel, Web-Analytics-Dienst etc. brauchen wir einen oder mehrere Streams. Adverity fragt dann die Daten beim Anbieter entsprechend der Konfiguration ab und lädt sie in das Data Warehouse.
Wir haben derzeit etwas über 200 Streams. Die Konfigurationen all dieser Streams händisch zu verwalten ist zwar möglich, aber fehleranfällig und nervtötend. Wie bereits im oben verlinkten Beitrag beschrieben, nutzen meist mehrere Betriebe des Unternehmens die gleichen Plattformen – nur mit unterschiedlichen Accounts. Da bietet es sich an, die für eine Plattform benötigten Streams nur einmal zu definieren und mit kleinen Änderungen für alle Betriebe des Unternehmens auszurollen.
Die Weboberfläche von Adverity bietet diese Möglichkeiten nicht, jedoch stellt Adverity eine API bereit, durch die wir viele Aspekte der Data Streams anpassen können.
Stream-Management per API
Unser Ansatz besteht aus zwei Teilen:
• Eine detaillierte Beschreibung aller Streams durch Konfigurationsdateien
• Ein Programm, das durch API-Aufrufe sämtliche Streams auf den Soll-Zustand bringt
Wenn also zum Beispiel ein neues Feld für alle “Search Term Performance”-Streams benötigt wird, kann dieses im entsprechenden Template eingetragen werden. Das Programm passt danach alle Streams entsprechend an.
Strukturierte Konfiguration
Die Konfiguration erstreckt sich über eine Vielzahl von Dateien. Durch die Aufteilung auf mehrere Dateien bleiben die einzelnen Dateien (relativ) übersichtlich und haben jeweils einen klar umrissenen Anwendungsbereich. Wäre alle Konfiguration in einer einzelnen Datei, so hätte diese über 7.500 Zeilen.
Jede Konfigurationsdatei hat eine bestimmte Rolle:
• Stream-Template: Beschreibt einen konkreten Stream
• Stream-Set: Beschreibt eine Sammlung von Streams, z. B. alle Streams für eine Plattform
• Workspace: Beschreibt die Streams für einen Betrieb durch die Einbindung von Stream-Sets und/oder einzelnen Stream-Templates
• Hauptkonfiguration: Enthält eine Liste der Workspaces und globale Einstellungen wie z. B. die API-URL
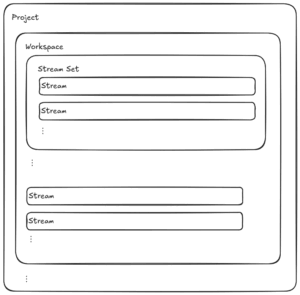
Durch den Einsatz von Variablen in der Konfiguration können Streams angepasst werden. Werte werden von oben (Hauptkonfiguration) nach unten (einzelner Stream) durchgereicht und können auf jeder Ebene angepasst, erweitert oder überschrieben werden.
Zum Beispiel werden alle Instagram-Medien-Streams die gleichen Felder abfragen. Der Name des Streams und der Account, den er nutzt, sollen aber pro Betrieb konfiguriert werden.
Im Workspace des Betriebs definieren wir dafür zwei Variablen:
|
# Die folgenden 2 Zeilen „aktivieren“ Instagram für den Betrieb:
[[stream_sets]]
include = „sets/instagram_organic.toml“
# Variablen für die Produktiv-Umgebung:
[variables.prod]
name_infix = „Zentrale“ # Wird später Teil des Stream-Namens
instagram_auth = 154 # ID der zu nutzenden Instragram-Authorisation
|
In der Konfiguration für das Instagram-Stream-Set können wir diese Variablen dann entsprechend nutzen:
|
[[streams]]
name = { subst = „IG_${name_infix}_Media_Lifetime_Daily“ }
# ergibt: name = „IG_Zentrale_Media_Lifetime_Daily“
auth = { ref = „instagram_auth“ }
# ergibt: auth = 154
template = „templates/instagram/ig_media_lifetime.toml“
|
Diese Aufteilung bietet eine hohe Wiederverwendbarkeit von Komponenten und bleibt gleichzeitig sehr flexibel.
One Tool to rule them all
Die zentrale Funktion des Tools, das wir zur Verwaltung der Adverity-Workspaces entwickelt haben, ist der Abgleich von Ist- mit Soll-Zuständen – und auf Wunsch auch die Herbeiführung des Soll-Zustands.
Dazu fragt das Tool die aktuelle Konfigurationen aller Adverity-Streams ab und speichert sie in einem internen Datenmodell. Dieses Datenmodell wird dann mit der Konfiguration abgeglichen, um eine Liste notwendiger Änderungen zu erstellen. Kleinere Abweichungen werden bewusst akzeptiert, solange sie keine Auswirkungen auf das finale Datenprodukt haben. Diese Änderungen zeigt das Tool dann an und kann sie auf Wunsch auch direkt durchführen.
Zusätzlich kommen noch hilfreiche Features dazu, wie die Steuerung von “Fetches”, die Generierung von Templates aus existierenden Streams, das Rendern von Text-Templates mit Informationen aus der Konfiguration und von Adverity, sowie diverse weitere kleine Helferlein.
Als Programmiersprache für das Programm haben wir Rust gewählt. Diese Wahl mag auf den ersten Blick ungewöhnlich erscheinen – ist Python doch im Datenbereich viel weiter verbreitet.
Rust ist bekannt für seine Performance und Speichersicherheit – beides Eigenschaften, die zwar in jedem Projekt vorteilhaft sind, bei einem internen Tool dieser Art aber nicht den Ausschlag geben.
Dennoch hat sich Rust im Nachhinein als die richtige Wahl herausgestellt. In der Anfangsphase, in der wir die Grundlagen geschaffen haben, haben wir zwar mehr Arbeit investiert, als es mit Python der Fall gewesen wäre. Danach jedoch hat die Entwicklung danach eine gute Geschwindigkeit aufgenommen. Neue Features konnten wir im Verlauf des Projekts schnell (meist innerhalb weniger Stunden) und ohne Angst vor ungewollten Seiteneffekten entwickeln.
Vor allem die starke Typisierung und erzwungene Fehlerbehandlung sind dabei sehr hilfreich. Was anfangs vielleicht wie Over-Engineering aussah hat sich später mehrfach ausgezahlt: Durch die rapide Weiterentwicklung und den stabilen sowie fehlerfreien Betrieb.
Mit dieser Entscheidung stehen wir nicht allein auf weiter Flur. Auch unser Partner dbt labs, der uns kürzlich als “Emerging Partner of the Year” ausgezeichnet hat, geht diesen Weg. Sie entwickeln das Kernstück ihres Produkts – dbt core – unter dem Namen dbt Fusion engine in Rust neu. Seit Kurzem ist dbt Fusion engine in Public Preview.
Fazit
Mit dem hier beschriebenen Ansatz haben wir einen entscheidenden Schritt gemacht: Sowohl manuell gepflegte Daten als auch automatisiert geladene Datenströme lassen sich nun vollständig nachvollziehbar, konsistent und skalierbar in das föderierte Data Warehouse integrieren.
Änderungen an hunderten Streams, die sonst Stunden oder Tage gedauert hätten, sind in Minuten umgesetzt. Neue Plattformen oder Betriebe lassen sich mit minimalem Aufwand einbinden, und bestehende Strukturen bleiben jederzeit nachvollziehbar und auditierbar.
Damit haben wir nicht nur die technische Grundlage geschaffen, sondern auch die operative Skalierbarkeit erreicht, die ein föderiertes Data-Warehouse-System dieser Größenordnung benötigt. Kurz gesagt: Wir haben ein komplexes, fehleranfälliges Setup in ein wartbares, robustes und elegantes System verwandelt – und zeigen damit, wie durchdachte Automatisierung und sauberes Engineering einen echten Mehrwert schaffen.
Dieser Use Case verdeutlicht, warum die Wahl der richtigen Plattform entscheidend ist. Um solche komplexen Multi-Mandanten-Szenarien performant und sicher abzubilden, vertrauen wir auf die Snowflake Data Cloud.
Möchtest Du erfahren, wie wir Snowflake nutzen, um auch Deine Datenstruktur zukunftssicher und hochskalierbar aufzubauen?
Erfahre mehr über unsere Expertise in der Snowflake
JETZT BERATUNGSTERMIN ANFRAGEN




 (24)")


