




Am 15. Juli war es soweit: Wir hatten intern ein dbt-Training, durchgeführt von unseren Kollegen aus UK – Ollie Clarke und Jonathan MacDonald. Ollie ist unser zertifizierter dbt-Trainer und hat bereits zahlreiche Schulungen gehalten. Viele unserer Kunden arbeiten inzwischen mit dbt, und aktuell unterstützen über 15 unserer Consultants dabei, dbt in deren Organisationen erfolgreich einzuführen.
Letzte Woche durfte ich selbst an dem Training teilnehmen. Es war spannend, mehr über die Entwicklung von dbt zu erfahren und tiefer in das Tool einzutauchen, um sein volles Potenzial kennenzulernen. Das Highlight war definitiv die Hands-on-Session, bei der wir direkt in einem Projekt arbeiten konnten. Ollie hat das Ganze mit viel Engagement anhand des Lego-Datensatzes gestaltet.
Alle Teilnehmenden – mich eingeschlossen – sind begeistert: das Tool ist einfach großartig!
Aber was ist dbt eigentlich?
dbt (data build tool) ist ein Open-Source-Framework, welches von dbt Labs entwickelt wird um komplexe Daten-Transformationen direkt im Data Warehouse zu organisieren. In der Welt von ELT (Extract, Load, Transform) steht dbt für den Buchstaben T – Transform. Diese Grafik zeigt, wo sich dbt im modernen BI-Stack einordnet:
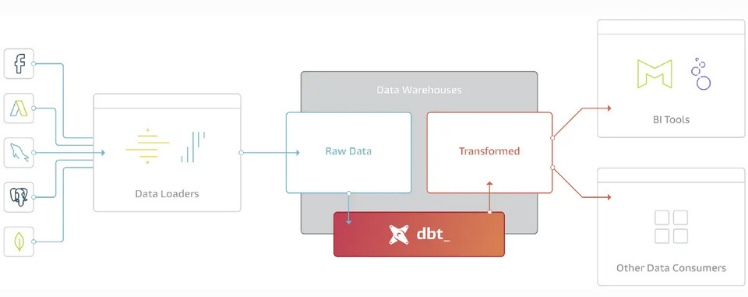
Innerhalb des Data Warehouse hilft dbt dabei, die Komplexität moderner Daten-Pipelines in den Griff zu bekommen. Damit können Data Engineers SQL-Modelle schreiben, die genau definieren, wie Rohdaten Schritt für Schritt in saubere, analysierbare Daten verwandelt werden.
Das Besondere: dbt bringt viele Best Practices aus der Softwareentwicklung in die Welt der Daten. Dazu gehören Versionierung, Tests, Dokumentation und automatisierte Deployments. So wird aus oft unübersichtlichen SQL-Skripten ein transparentes, wartbares und skalierbares Datenmodell. Wie der Weg von Rohdaten zu transformierten Daten aussieht, zeigt diese Visualisierung:
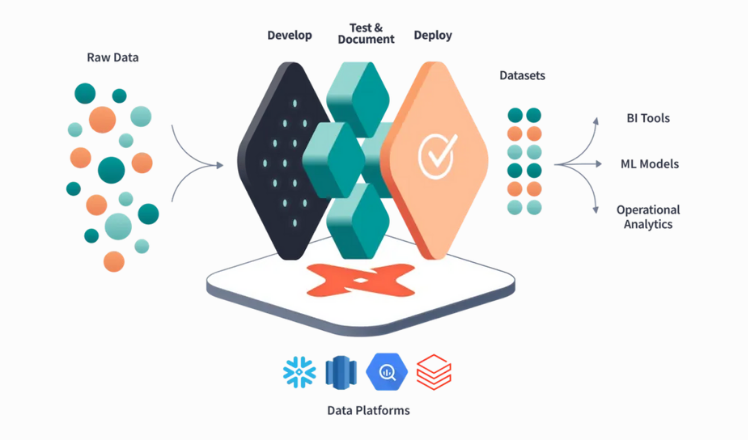
Schauen wir ihn uns Schritt für Schritt an:
1. Develop:
Transformationen und Business-Logik werden definiert, um Rohdaten zu standardisieren und für nachgelagerte Analysen vorzubereiten. Mithilfe von CI/CD können Nutzer ihren Code aus dem Versions-Repository automatisiert in eine Testumgebung überführen.
2. Test & Dokumentation:
Bevor Modelle in Produktion gehen, werden sie getestet. Automatisierte Tests helfen dabei, Fehler frühzeitig zu erkennen und die Datenqualität dauerhaft zu sichern. Gleichzeitig wird die Dokumentation automatisch und dynamisch generiert, damit alle im Team wissen, wie die Modelle aufgebaut sind und was ihr Zweck ist.
3. Deploy:
Die geprüften Modelle werden automatisiert in die Produktionsumgebung überführt. In diesem Schritt wird Git für Version Control genutzt, damit Änderungen jederzeit nachvollziehbar sind.
Mit dbt wird also klar nachvollziehbar, wie Datenflüsse aufgebaut sind, woher Kennzahlen stammen und was wann berechnet wird. Gerade in wachsenden Datenprojekten sorgt das für mehr Qualität, weniger Fehler und eine deutlich höhere Entwicklungsgeschwindigkeit.
Zusammengefasst: dbt kann …
✔ SQL in einer skalierbaren, wartbaren und versionierbaren Weise schreiben
✔ Abhängigkeiten und Lineage automatisch erkennen
✔ Tests einfach auf Daten anwenden
✔ Dokumentationen automatisch erstellen
✔ Den Aufbau, die Pflege und die Aktualisierung des Data Warehouse automatisieren
Wenn Sie mehr über dbt erfahren möchten, es selbst einsetzen wollen oder allgemein Fragen zu Data Engineering oder DataOps haben – melden Sie sich gerne bei uns! Wir teilen unser Wissen nicht nur intern, sondern auch mit allen, die sich für moderne Datenarbeit interessieren.
Data Engineering bei The Information Lab
An dieser Stelle nochmal der Hinweis: The Information Lab bietet Unterstützung im Data Engineering an! Neben unseren bekannten Stärken in Business Intelligence, Analytics und Datenvisualisierung unterstützen wir unsere Kunden auch dabei, ihre Datenplattformen technisch robust und nachhaltig aufzubauen.
Das bedeutet konkret:
✔ Moderne Datenarchitekturen designen
✔ Daten-Pipelines automatisieren
✔ Datenqualität sichern
✔ Tools wie dbt (und viele andere) nahtlos integrieren
✔ Prozesse nach DataOps-Prinzipien aufsetzen
Mit unserem wachsenden Data-Engineering-Team machen wir genau das möglich. Der Bereich Data Engineering ist neu strukturiert und das Team wurde noch mal verstärkt. So sind wir in der Lage, den gesamten Datenprozess zu begleiten: von der Extraktion der Rohdaten bis hin zum fertigen Bericht!
Lust auf ein dbt-Pilotprojekt? → Jetzt Kontakt aufnehmen
Bei The Information Lab sind wir überzeugt: Gute Datenarbeit lebt vom Austausch. Deshalb freuen wir uns über jede Frage, jede Diskussion und jeden Einblick von außen. Ob erste Fragen zu dbt, konkrete Data-Engineering-Projekte oder ein tieferer Austausch zu DataOps – wir stehen gerne mit Rat und Tat zur Seite.
Mehr zum Thema Data Engineering finden Sie unter unseren Service: Data Engineering
Sie haben bereits eigene Use Cases, über die Sie sprechen möchten? Hervorragend! Wir schauen uns Ihre Anforderungen gemeinsam an, teilen unsere Erfahrungen und geben Ihnen ehrliches, praxisnahes Feedback, damit Sie das Maximum aus Ihren Daten herausholen können.
Melden Sie sich einfach bei uns – wir freuen uns darauf, mit Ihnen ins Gespräch zu kommen!
Mehr über dbt erfahren Sie hier: dbt


