




Kundenabwanderung (engl. Customer Churn) ist ein Problem, das jede Branche beschäftigt. Einen Neukunden zu gewinnen ist bekanntlich fünfmal so teuer, wie einen Bestandskunden zu behalten. Gezielte Marketing- und Account-Management-Aktivitäten sind also erfolgsentscheidend, insbesondere solche, die nicht erst auf eine Kündigung reagieren, sondern sie proaktiv verhindern – ein ideales Spielfeld für intelligente Algorithmen. Wir wollen uns an einem konkreten Beispiel anschauen, wie wir ein bestehendes Customer Churn Reporting mithilfe von Machine Learning weiterentwickeln können, indem wir es mit KI-gestützten Vorhersagen anreichern.
Wir nutzen hier einen frei verfügbaren Datensatz eines fiktiven Telekommunikationsanbieters. Die Originaldaten haben wir so aufbereitet und vereinfacht, dass die für uns relevanten Informationen übrig bleiben.
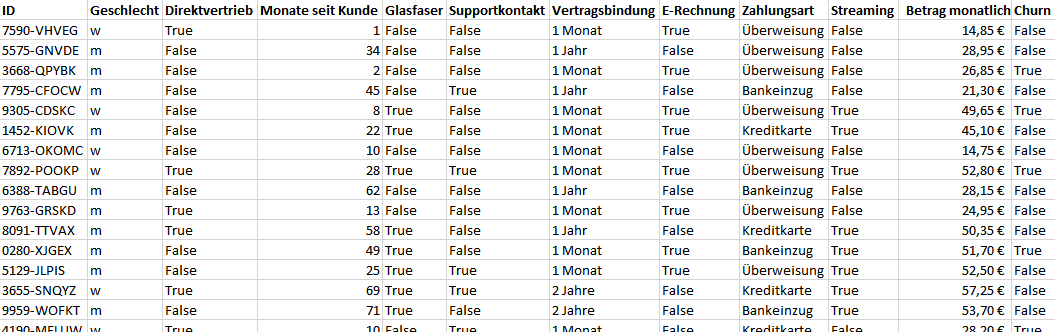
Zu unseren knapp 5.000 Kunden haben wir verschiedene Vertragsdetails, Nutzungsmetriken und Personendaten. Außerdem sagt uns das Feld Churn, ob der Kunde innerhalb des letzten Monats abgewandert ist (True), also seinen Vertrag gekündigt hat oder uns bis dato treu geblieben ist (False). Kunden, die bereits früher abgewandert sind, sind im Datensatz nicht mehr enthalten. Die Daten enthalten also immer unsere gesamten Bestandskunden sowie die kürzlich abgewanderten Kunden. Auf Basis dieser Daten haben wir bereits einen Customer Churn Report im Einsatz, der uns die jeweils aktuellen Zahlen zeigt.
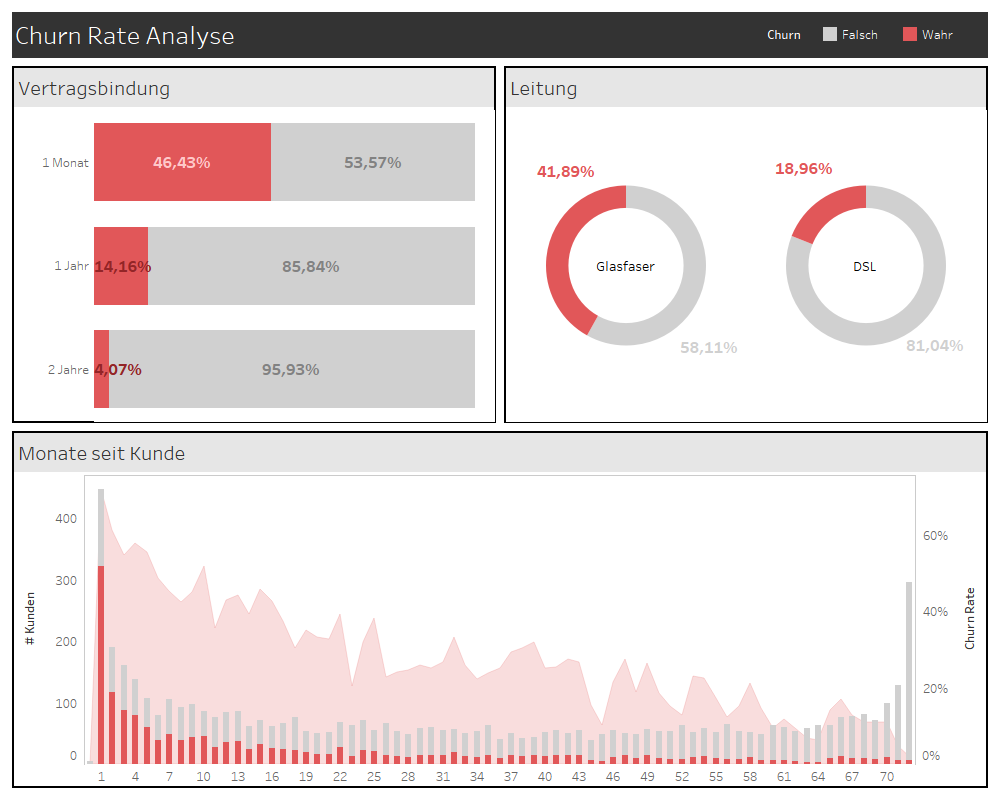
Durch manuell-visuelle Analyse haben wir verschiedene Zusammenhänge identifiziert und die Churn Rate (hier definiert als den Anteil der zuletzt abgewanderten Kunden am Datensatz) nach den jeweiligen Kundenmerkmalen, wie Vertragsbindung, Bestandsdauer und Internetleitung, dargestellt. So haben wir z.B. erkannt, dass Kunden mit monatlicher Vertragsbindung deutlich häufiger abwandern als Kunden mit jährlicher oder zweijähriger Bindung. Außerdem sehen wir, dass die Wahrscheinlichkeit, dass ein Kunde abwandert, mit der Zeit abnimmt. Die Kundentreue verfestigt sich gewissermaßen selbst. Deshalb haben wir vor Kurzem eine Marketingkampagne gestartet, die diejenigen Kunden, die noch nicht lange bei uns sind und einen monatlich kündbaren Vertrag abgeschlossen haben, zum Wechsel zur jährlichen Bindung bewegen soll.
So weit, so gut. Aber steckt nicht noch mehr in unseren Daten? Hier kommt die automatisierte Modellierung ins Spiel. Um Produktentwicklung, Account Management und Marketing wirklich datengetrieben zu steuern, brauchen wir erstens eine Churn-Wahrscheinlichkeit für jeden einzelnen Kunden und zweitens eine Automatisierung des entsprechenden Analyseprozesses. Dazu wollen wir die Variable Churn mithilfe eines Machine Learning Algorithmus aus den anderen Kundenmerkmalen heraus modellieren. Der Algorithmus soll also aus den aktuell vorhandenen Daten einen allgemeingültigen mathematischen Zusammenhang zwischen der Zielvariablen und den sogenannten Prädiktoren ableiten.
Wichtig ist dabei zunächst, eine Abgrenzung zwischen historischen und neuen Daten vorzunehmen. Jeder Kunde ist zum aktuellen Zeitpunkt entweder abgewandert oder (noch) nicht abgewandert und hat im Datensatz das entsprechende Label (True/False). So gesehen sind all unsere Daten historische Daten. Wenn wir aber auf diesen Daten ein Modell trainieren, können wir es anschließend nicht zur Vorhersage der Churn-Wahrscheinlichkeit derselben Kunden nutzen – wir würden einen Zirkelschluss anwenden. Es gibt verschiedene Möglichkeiten, mit dieser Problematik umzugehen. Häufig werden die Daten historisiert und die so entstehende Kette von Momentaufnahmen der Vergangenheit zum Modelltraining benutzt. Ein solches Modell liefert anschließend Vorhersagen der Churn-Wahrscheinlichkeit für die jeweils aktuelle Version der Daten. Ähnlich verfährt man auch im Nicht-Kontrakt-Geschäft, wo eine Abwanderung nicht direkt anhand einer Kündigung festgestellt werden kann, sondern sich z.B. im längeren Ausbleiben neuer Käufe äußert.
Für unser Beispiel vereinfachen wir die Situation etwas und machen uns den schon erwähnten Zusammenhang zwischen der Churn Rate und der Zeit, seit der ein Kunde bei uns ist, zunutze. Tatsächlich verlieren wir ein Drittel unserer Kunden innerhalb der ersten 3 Monate nach Vertragsabschluss.
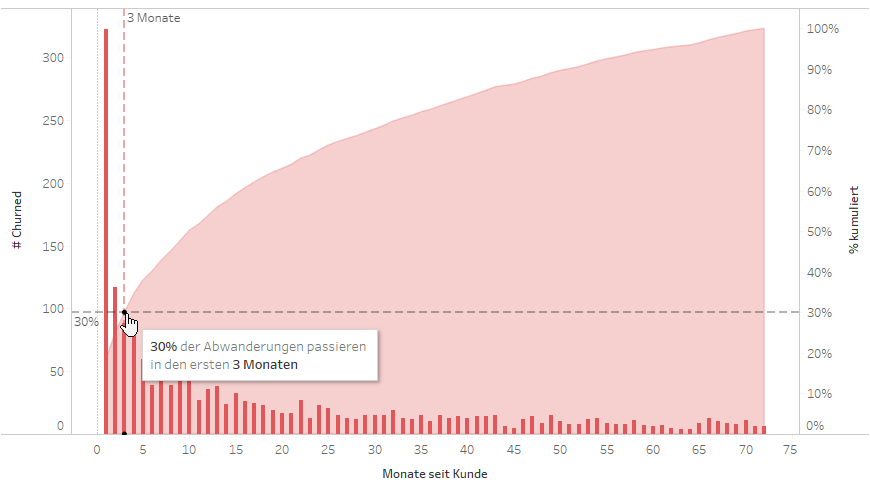
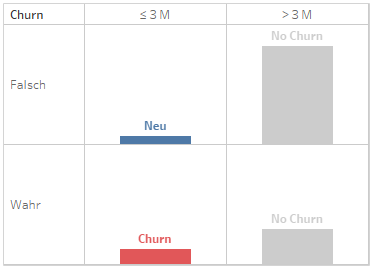
Wenn wir es schaffen, diese Neukunden zu binden, haben wir einen starken Hebel, um der Abwanderung nachhaltig entgegenzuwirken. Wir wollen also die Churn-Wahrscheinlichkeit für diejenigen Kunden vorhersagen, die noch nicht länger als 3 Monate bei uns sind, und betrachten die Daten aller anderen Kunden als historisch. Dabei schreiben wir das ursprüngliche Churn-Label entsprechend unserer 3-Monats-Grenze um und werten nur noch diejenigen Kunden als abgewandert, die uns innerhalb der ersten 3 Monate verlassen haben. Alle Kunden, die mindestens 3 Monate bei uns geblieben sind, betrachten wir für unser Modell als Erfolg (Nicht-Churner).
Die Datenaufbereitung und die komplette Modellentwicklung setzen wir in Alteryx Designer um. Mit dem Intelligence Suite Add-On lassen sich Machine Learning Pipelines ganz ohne KI- und Programmierkenntnisse umsetzen, dokumentieren und produktivieren. Die Umsetzung in anderen Tools oder Programmierumgebungen folgt aber demselben Vorgehen. Auf die Vielfalt der Modelle und Algorithmen gehen wir an dieser Stelle nicht näher ein. Grundsätzlich wollen wir aus verschiedenen Modelltypen den bestgeeigneten auswählen und für unseren Anwendungsfall optimieren. Um dabei eine Überanpassung des Modells an unsere derzeit vorliegenden Daten und damit eine schlechte Performance auf neuen Daten zu verhindern, ziehen wir immer wieder zufällige Stichproben, die wir mal zum Trainieren, mal zum Testen des Modells verwenden. Am Ende haben wir verschiedene, jeweils auf unseren Anwendungsfall optimierte Modelle, deren voraussichtliche Vorhersagegenauigkeit wir vergleichen können. Das beste Modell nutzen wir anschließend für die Vorhersage der Zielvariablen in unseren neuen Daten.
Viele dieser Schritte müssen wir dabei nicht händisch umsetzen. Alteryx erlaubt uns zu entscheiden, inwieweit wir als Nutzer in die Modellentwicklung eingreifen wollen. Statt das iterative Trainieren, Testen und Anpassen der Modelle im Workflow selbst aufzubauen, können wir verschiedene Ebenen der Automatisierung wählen, ganz nach unseren Fähigkeiten und Bedürfnissen.
Wollen wir stärker Einfluss auf die Modellbildung nehmen, können wir z.B. für eine Balance von Churn- und Nicht-Churn-Fällen sorgen, indem wir die Daten entsprechend vorfiltern oder die Modellparameter justieren. So können wir die Genauigkeit der Vorhersagen in eine bestimmte Richtung steuern, die unseren praktischen Anforderungen entspricht. Hier lohnt es sich, die getesteten Klassengenauigkeiten näher zu untersuchen.
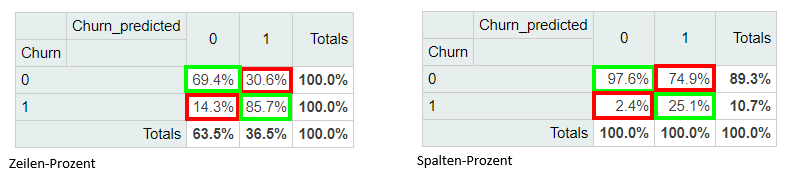
Beim randomisierten Testen unseres Modells gegen die historischen Daten werden 85,7% der Churner und 69,4% der Nicht-Churner korrekt klassifiziert (links). Das sind gute Performancewerte, und den Kompromiss zwischen Falsch-Positiven und Falsch-Negativen Klassifizierungen müssen wir in der Praxis immer eingehen. Wir sehen an diesen Zahlen bereits, dass das Modell dazu neigt, im Zweifel eher einen Churn als einen Nicht-Churn zu melden: 30,6% der treu gebliebenen Kunden (Churn = 0) werden fälschlicherweise als Churner erkannt (Churn_predicted = 1), dafür ist die Fehlerquote bei den abgewanderten Kunden mit 14,3% nur etwa halb so hoch (Churn = 1, Churn_predicted = 0). Noch deutlicher wird diese Neigung beim Vergleich der Genauigkeit der vorhergesagten Klassen (rechts). Fast 75% der vorhergesagten Churner sind falscher Alarm. Das klingt nach einem schlechten Modell. Dafür können wir uns aber bei der Modellvorhersage „Nicht-Churn“ zu 97,6% sicher sein, dass dieser Kunde tatsächlich in den ersten 3 Monaten nicht abwandert. Da es ungleich teurer ist, einen abwandernden Kunden nicht rechtzeitig zu erkennen, als einen zufriedenen Kunden ohne Not anzusprechen, ist dieses Ungleichgewicht unterm Strich genau das, was wir wollen.
Am Ende der Modellentwicklung haben wir nicht nur ein robustes Modell mit ausgewogener Vorhersagegenauigkeit, sondern auch Erkenntnisse darüber, wie stark die verschiedenen Merkmale unserer Kunden deren Churn-Wahrscheinlichkeit beeinflussen. Die assistierte Modellierung in Alteryx zeigt uns die Ergebnisse automatisch an. Dass die Vertragsbindung stark mit der Abwanderungswahrscheinlich innerhalb der ersten 3 Monate zusammenhängt, liegt auf der Hand. Tatsächlich sollten wir dieses Merkmal vielleicht aus der Modellbildung ausschließen. Aber auch die Art des Vertriebs und der monatliche Rechnungsbetrag sind Einflussgrößen, die wir in unserem bisherigen Reporting nicht beachtet haben.
Ist das Modell entwickelt, können wir einerseits den Output der konkreten Vorhersagen an unsere bestehenden Kundendaten anspielen und den Trainings- und Vorhersageprozess immer wieder auf Basis der neuesten Daten ausführen. Andererseits können wir auch das Modell selbst auf einem Server veröffentlichen und etwa per API-Endpunkt für Vorhersage-Anfragen aus beliebigen Anwendungen zur Verfügung stellen. Hier sind verschiedene Produktionsszenarien denkbar, die mit kleinerem oder größerem Aufwand Management, Monitoring und Verfügbarkeit unserer Modelle sicherstellen. In jedem Fall müssen wir die Modellperformance laufend prüfen und die Modellparameter bei Bedarf anpassen.
Zum Abschluss unseres Beispiels wollen wir den einfachsten Weg wählen und die aktuellen Vorhersagen direkt in unseren Report einbinden.
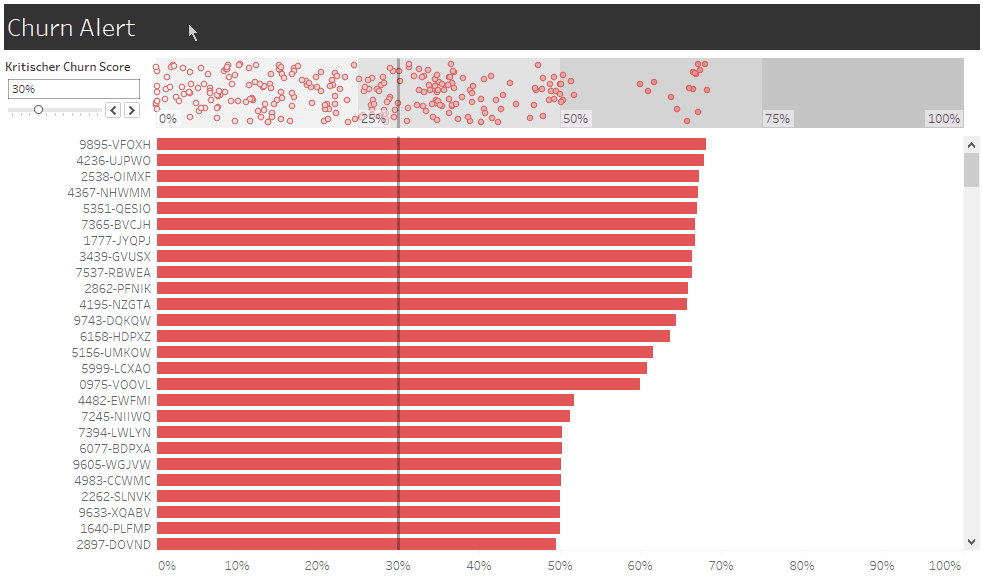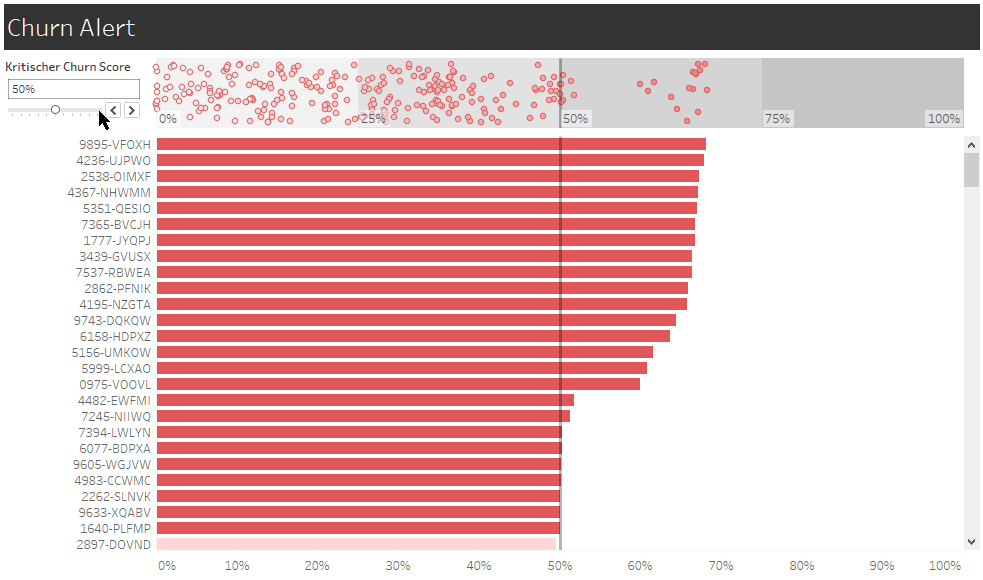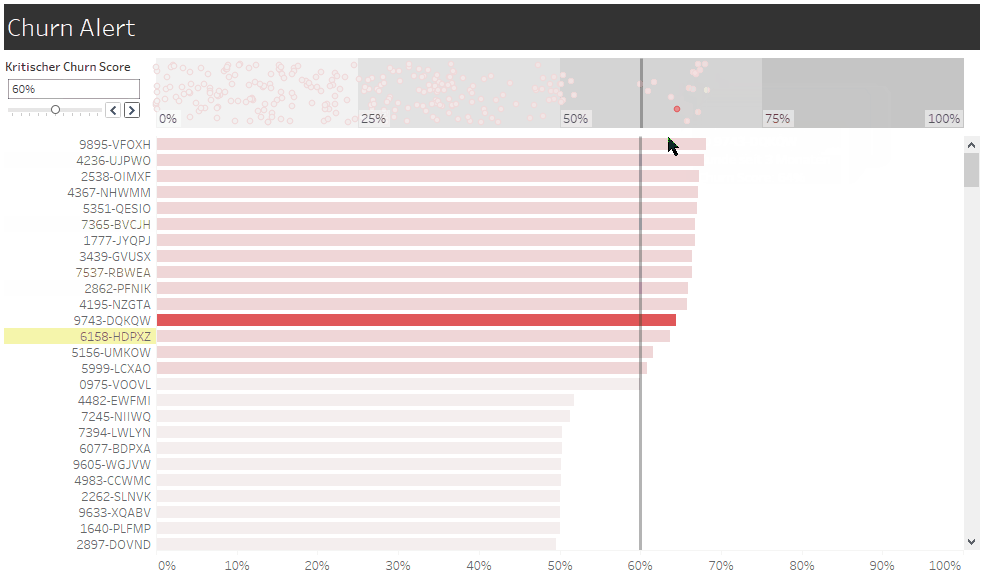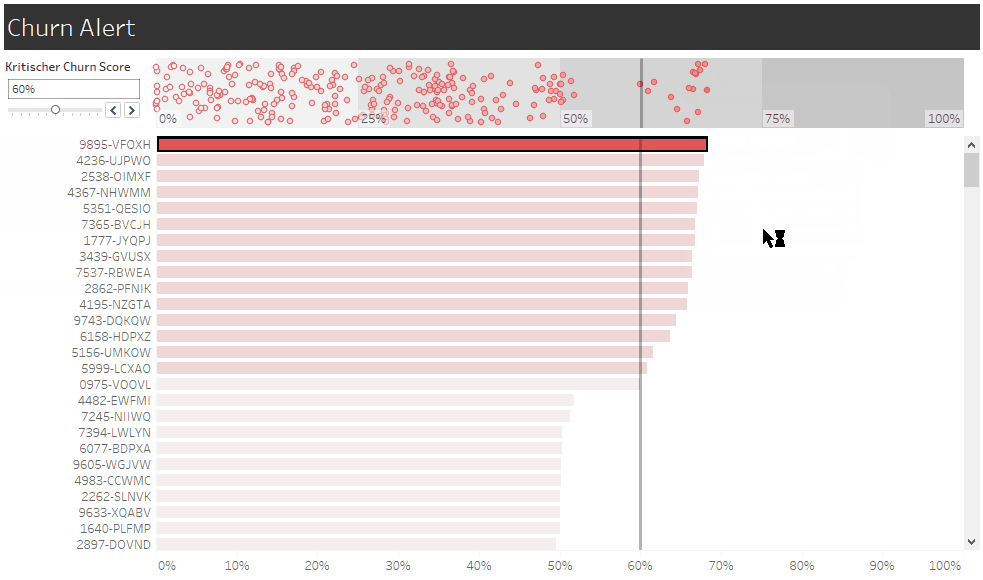
Eine neue Ansicht dient uns als Churn-Alarm und macht die Ansprache konkreter Kunden durch Account Management oder Marketing möglich. Der individuelle Churn Score ist hier die Churn-Wahrscheinlichkeit, die unser Modell dem Kunden aktuell zuweist. Zukünftig könnten wir diesen Score aber noch durch Informationen nachjustieren, die nicht in das Modell einfließen, wie etwa den Stellenwert des Kunden für unser Unternehmen. Denn kein Modell wird je alle Informationen berücksichtigen, die für unsere Handlungsentscheidungen relevant sind.
Machine Learning ist ein mächtiges Werkzeug in der Toolbox der Business Intelligence. Sein Nutzen hängt davon ab, ob wir es sinnvoll einzusetzen wissen.
Sie haben eine Idee für ein Machine Learning Projekt, wissen aber nicht, wie Sie diese konkret umsetzen können? Dann kommen Sie gerne auf uns zu! Hier geht es zur kostenfreien virtuellen Beratungs-Session. Mehr zu den Gründen, warum Machine Learning Projekte scheitern, erfahren Sie in unserem Blog. Ein On-Demand Webinar zum Thema Machine Learning finden Sie hier.
[button URL=“ [button URL=“https://forms.microsoft.com/Pages/ResponsePage.aspx?id=kBKJgOOduEuxo4qoRO3pY0hP_QF9G-NHqZoLayrnGMBUNkdUNkFLTDJIVjRGODFYNVlTTUFLTVREOSQlQCN0PWcu“]Zur Beratung[/button]
[button URL=“ [button URL=“https://register.gotowebinar.com/recording/7180434763954241795″]Zum Webinar[/button]
[button URL=“ [button URL=“https://theinformationlab.de/blog/3-gruende-warum-machine-learning-projekte-scheitern/“ target=“_self“]Zum Blog[/button]


