



Du würdest gerne eine Website „scrapen”, aber wie? Mit Alteryx kann man mit ein paar Tools in kurzer Zeit eine Website scrapen. Ich werde euch heute zeigen, wie man das schafft. Als Beispiel werden wir die Bücher-Website http://books.toscrape.com/ benutzen. Diese Website ist ein Buchhändler und wir werden die Produktinformationen (Buchtitel, Preis und Bewertung) scrapen.
Unabhängig davon, auf welcher Website wir uns gerade befinden, befindet sich HTML-Code (Hypertext Markup Language) im Hintergrund. Dieser Code enthält die Daten, die wir scrapen möchten. Um diesen Code und entsprechenden Daten zu sehen, kann man einfach auf die Website rechtsklicken und „Seitenquelltext anzeigen” auswählen.
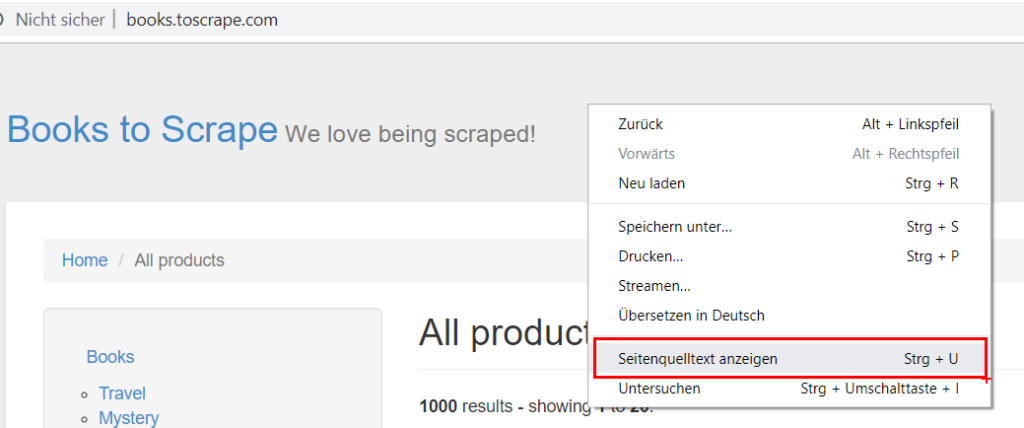
Man muss keinen HTML-Code schreiben können, um zu verstehen, dass die Produktinformation, die wir scrapen möchten, einem bestimmten Muster folgt. Zum Beispiel befindet sich die Bewertung von Büchern in dem Format „<p class=“star-rating Three“>”. In ein paar Schritten werden wir die entsprechenden Muster benutzen, um die Produktinformation „herauszuziehen”, zuerst aber müssen wir die Daten downloaden. Dafür benutzen wir das graue „Download”-Tool, an das wir ein grünes „Text Input”-Tool heften, um uns mit der Website-URL zu verbinden. Unser Workflow sollte so aussehen:
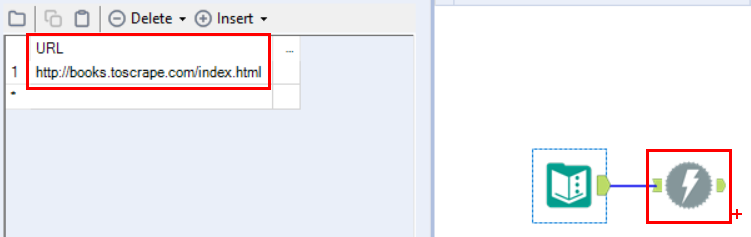
Wenn wir jetzt unseren Workflow durchlaufen lassen werden wir die gesamte Website in einer Spalte speichern.

Unser nächster Schritt besteht darin, diese große Zelle in kleinere „handlichere” Zellen aufzuteilen. Hierfür benutzen wir ein grünes „RegEx”-Tool (d.h. regular expression = regulärer Ausdruck), um eine Zelle pro Buch zu generieren. Man kann mehr über regulärer Ausdruck hier erfahren.
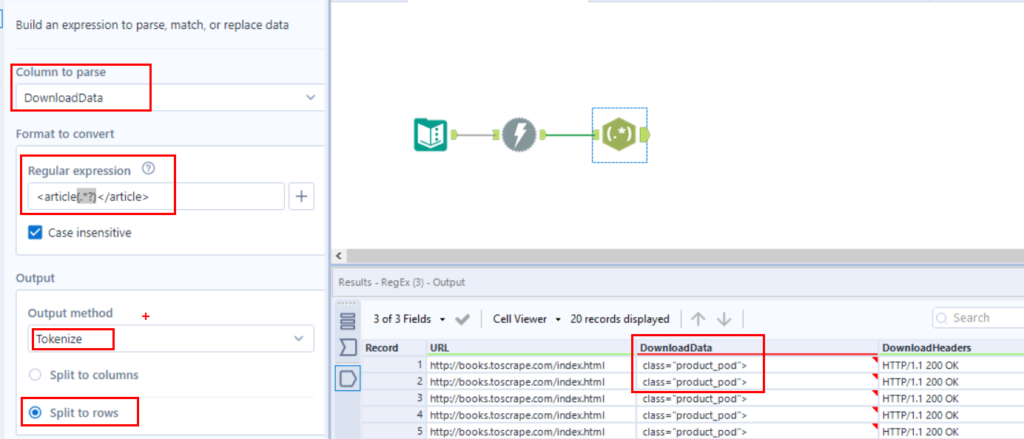
Oben sehen wir, wie dieses Tool verwendet wird. Unter „Columns to parse” selektieren wir die Spalte („DownloadData”), welche wir in Zeilen umwandeln möchten. Unter „Regular expression” formulieren wir das bestimmte Muster, das die Produktinformationen pro Buch enthält.
Im obigen Beispiel („<article(.*?)</article>”) extrahieren wir alles innerhalb der Klammern, von „<article bis zu </article>”. In das Output Feld spezifizieren wir, dass wir die Daten in sogenannten Tokens (wie einzelne Stücke) übersetzen möchten (ein Token pro Buch), und dass wir die Daten in Zeilen („Split to rows”) splitten möchten. Jetzt haben wir eine Zeile pro Buch, allerdings liegen die Daten (z.B. Titel und Preis), die wir extrahieren möchten, immer noch in einzelne Zellen vor. Dafür benötigen wir ein weiteres „RegEx”-Tool, um die Daten von jeder einzelnen Zelle zu extrahieren.
Unten sehen wir die Details für das zweite „RegEx”-Tool:
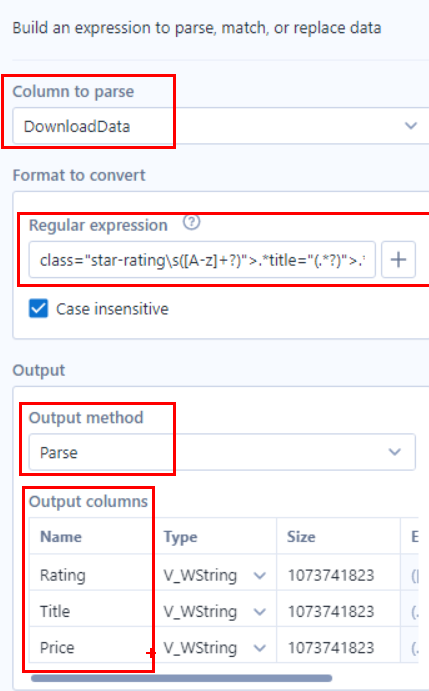
Wie im letzten Schritt extrahieren wir die gewünschten Daten aus der „DownloadData”-Spalte und wir benutzen einen „regulärer Ausdruck”, um Titel, Preis und Bewertung zu extrahieren. Dieses Mal möchten wir jedoch unsere Daten in Spalten umwandeln und verwenden daher die „Parse”-Methode. Unter „Output columns” können wir die Spalten sinnvoll umbenennen.
Und voilà, jetzt haben wir die gewünschten Daten in einzelnen Spalten:

Danach können wir ein „Output Data”-Tool verwenden, um die Daten zu exportieren und in Tableau zu visualisieren. Man kann auch weitere Tools verwenden, um die Eigenschaften zu ändern. Zum Beispiel könnte man ein „Formula”-Tool verwenden, um den Preis von Pfund zu Euro zu konvertieren, oder um die Bewertung in „integer”, also ganze Zahlen umzuwandeln.


