




Wir waren im Voraus darüber informiert worden, dass wir heute den Anfang eines recht komplizierten Themas lernen würden, nämlich reguläre Ausdrücke – eine Folge von Zeichen, die ein Suchmuster in einem Text festlegen. Die Musterregel von regex ist für das spätere Web Scraping von großer Bedeutung. Um ehrlich zu sein, war ich zunächst ziemlich schockiert, als ich eine lange, chaotische Folge von Sonderzeichen sah, die als Wildcards oder Steroide bezeichnet werden. Sie sind wahrscheinlich mit Wildcard-Notationen wie *.csv vertraut. Eine der häufigsten Verwendungen von Regex ist die Extraktion von Wörtern wie Text oder E-Mail-Adressen. Im Hinblick auf die enormen Anwendungsmöglichkeiten von Regex soll dieser Blog nur eine winzige Spitze des Eisbergs 😊, des faulen und gierigen Konzepts im Zusammenhang mit regulären Ausdrücken knacken.
In der Grundlektion werden Ihnen die folgenden Zeichen begegnen:

.* ist gierig, d.h. das nächste Begrenzungszeichen Ihrer Regex wird ignoriert, bis es selbst nicht erfüllt ist, es sei denn, die auf .* folgende Regex steht gegen das Ende der Zielzeichenkette.
.*? ist „ungreedy“, d.h. es fährt mit dem nächsten Begrenzungszeichen Ihrer Regex fort, wenn das nächste erfüllt ist. Er fährt mit dem nächsten Begrenzungszeichen fort, auch wenn er selbst noch anwendbar ist.
Lassen Sie uns mit einem Beispiel beginnen:
/(.*) dog/ passt zu Ich glaube, dein Hund hat meinen Hund gebissen und Gruppe 1 ist Ich glaube, dein Hund hat meinen Hund gebissen.
/(.*?) dog/ entspricht I think your dog bites my dog und Gruppe 1 ist I think your“.
Das ? macht das + „faul“ anstelle von „gierig“. Das bedeutet, dass es versucht, so wenige Übereinstimmungen wie möglich zu finden, anstatt so viele wie möglich.
Um die Dinge zu verdeutlichen, wollen wir die Suche Schritt für Schritt an einem anderen Beispiel nachvollziehen. Der Regex-Ausdruck /“.+?“/g funktioniert wie vorgesehen: Er findet „dein“ und „mein“:
- Der erste Schritt besteht darin, das Muster zu finden, das mit ‚ “ ‚:

2. Der nächste Schritt ist ebenfalls ähnlich: Die Maschine findet eine Übereinstimmung für den Punkt ‚.‘:

3. Und jetzt läuft die Suche anders. Da wir einen faulen Modus für +? haben, versucht die Maschine nicht, einen Punkt ein weiteres Mal zu finden, sondern hält an und versucht, den Rest des Musters ‚“‚ sofort zu finden:

4. Dann erhöht die Engine für reguläre Ausdrücke die Anzahl der Wiederholungen für den Punkt und versucht es ein weiteres Mal:

Erneutes Scheitern. Dann wird die Anzahl der Wiederholungen wieder und wieder erhöht…
5. …bis die Übereinstimmung mit dem Rest des Musters gefunden ist:
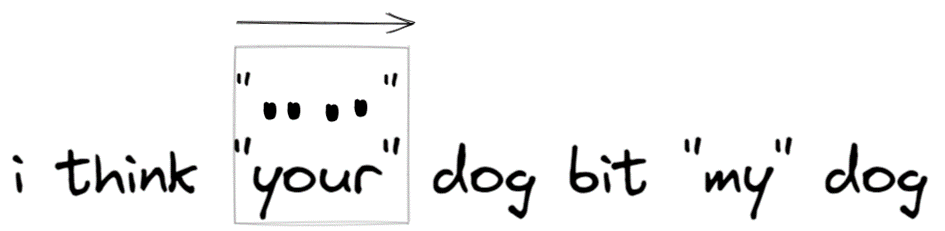
6. Die nächste Suche beginnt am Ende des aktuellen Treffers und liefert ein weiteres Ergebnis:
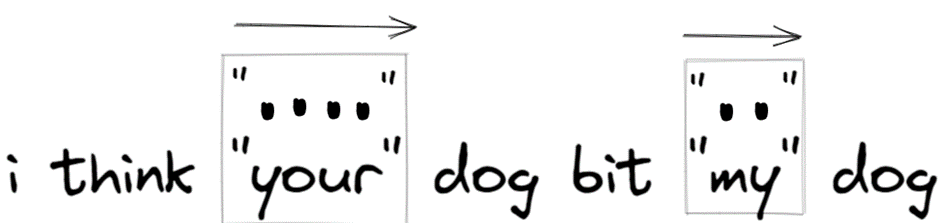
Wenn der Ausdruck wie /“.+“/ lauten würde, was „gierig“ bedeutet. Die Ergebnisübereinstimmung wäre „dein“ Hund biss „mein“
Das ist doch ein gutes Stück, das man am Freitag lernen kann, oder?


