



Tableau 2018.3 hat einige neue aufregende Features zu bieten. Eins davon ist, dass Hyper-Extrakte nun nicht mehr als einzelne Tabelle gespeichert werden müssen, sondern dass verknüpfte Tabellen als einzelne Datentabellen abgespeichert werden können. Das kann verschiedene Vorteile haben:
- Die Extrakt-Größe kann teilweise drastisch reduziert werden
- Die Extrakt-Ladezeit kann möglicherweise stark verkürzt werden
- Die Performance kann verbessert werden
Dadurch ergeben verschiedene Implikationen für einige Szenarien, wie zum Beispiel Row-Level-Security, größere Datensets mit mehreren Joins, oder allgemeine Use Cases, die eine Vervielfältigung von Zeilen durch Joins bedingen.
Der konzeptionelle Aufbau
Die Vorgehensweise für Row-Level-Security in Extrakten sieht folgendermaßen aus:
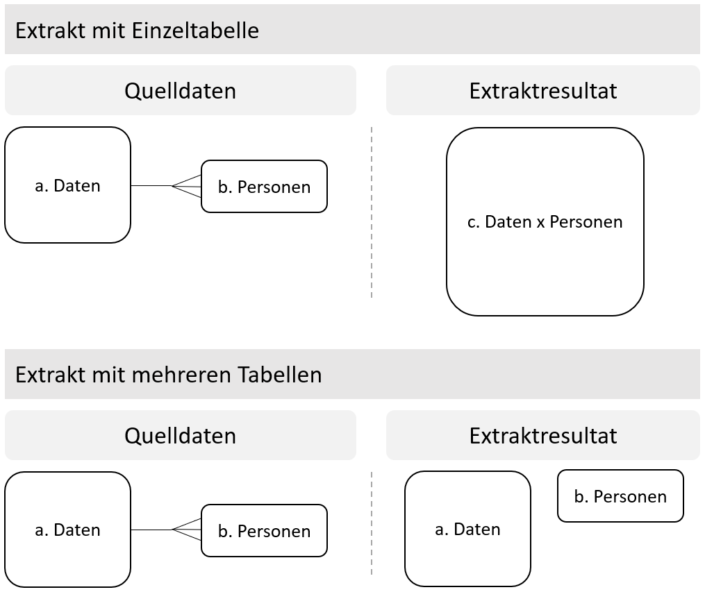
Üblicherweise ist es so, dass die gleiche Datenzeile von mehreren Personen gesehen werden darf, daher gibt es zwischen den Daten und der Personen-Tabelle eine 1-zu-N-Beziehung. Da Extrakte mit einer einzigen Resultat-Tabelle den Join schon ausmultiplizieren, ist die schlussendliche Tabelle deutlich „länger“ als die eigentlichen Daten, da diese mehrfach vorkommen. Das hat Auswirkungen auf die Größe des Extraktes und besonders auch die Zeit, die dieser zum Aufbau benötigt.
Die neue Funktionalität sorgt nun dafür, dass die Tabellen einzeln in der Hyper-Datenbank abgespeichert werden und dass der Join jeweils während der Abfrage ausgeführt ist. Das führt zu einer deutlich kleineren Extrakt-Datei und einer schnelleren Ladezeit.
Ein Beispiel mit Row-Level-Security
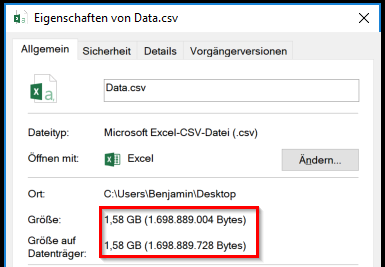
In einem durchgeführten Test hatte die Daten-Tabelle 100 Mio. Zeilen, die im .csv-Format 1,59 GB groß war. Multipliziert mit einer Personen-Tabelle von 4 Personen ergibt sich eine Zeilenanzahl von 180 Mio. Zeilen (1-zu-N).
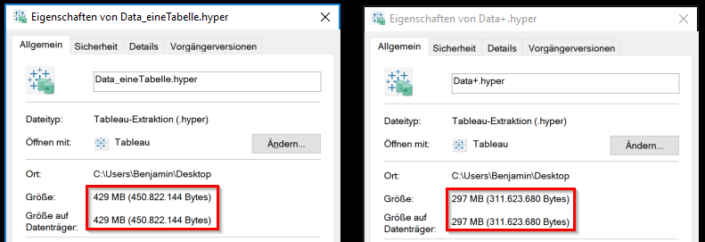
Beim Import nach Hyper über Tableau Desktop wurde beim Einzeltabellen-Extrakt der Join ausgeführt, damit wurden alle 180 Mio. Zeilen importiert. Bei der Einstellung mit mehreren Tabellen wurden lediglich die 100 Mio. Datensätze importiert und dazu die wenigen Datensätze aus der Personentabelle. Letzteres ging deutlich schneller. Auch die fertigen Hyper-Files hatten sehr unterschiedliche Größen, die erste hat eine Größe von 429 MB, die zweite eine Größe von 297 MB.
Die Umsetzung in Tableau
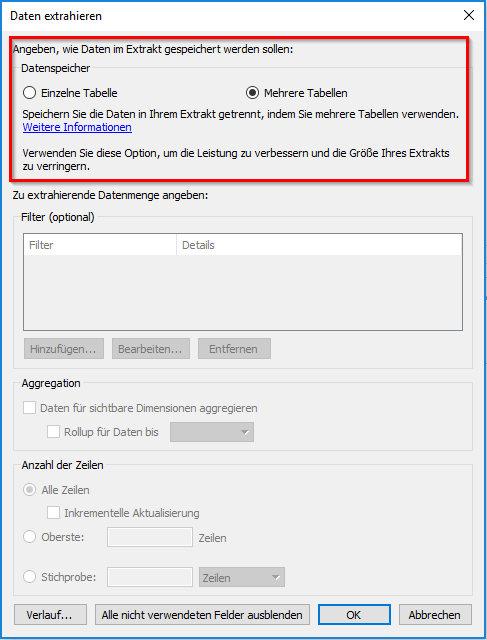
Die Auswahl des Features in Tableau ist ein einfacher Klick während der Extrakterstellung. So kann in dem Pop-Up-Fenster einfach die Auswahl „Mehrere Tabellen“ gemacht werden.
Einschränkungen
Leider hat das Feature noch einige Einschränkungen. Sobald die Option ausgewählt ist, können beispielsweise keine Extraktfilter mehr gesetzt werden, auch Aggregation und inkrementelle Updates sind noch nicht möglich. Tableau arbeitet jedoch daran, diese Möglichkeiten auch einzubauen. Eine Filterung der Daten könnte man aber beispielsweise durch die Verbindung von Custom SQL-Abfragen oder Datenbank-Views erreichen, die in Hyper als einfache Tabelle gespeichert werden.
Wann sollte das Feature genutzt werden und wann nicht?
Die Unterschiede zwischen den Optionen werden erst bei größeren Datenmengen sichtbar. Mehrere Tabellen können dabei schlechter sein, wenn Zeilen nicht vervielfältigt werden, da dabei der Join der Tabellen bei jeder Abfrage ausgeführt wird. Auch bei Extrakten, die nicht alle Daten erfordern, oder die aggregiert werden können, sind einzelne Tabellen aufgrund der stark verringerten Zeilenanzahl möglicherweise vorzuziehen.
Grundsätzlich sollte – gerade bei größeren Datenmengen – geprüft und getestet werden, welche Variante eine bessere Performance bedeutet und wie die Prioritäten bzgl. der Ladezeit und der Dateigröße sind.
Weitere Informationen können auch unter folgenden Ressourcen abgerufen werden: Multiple Table (Normalized) Hyper Extracts, Multiple Table Storage for Extracts und Informationen zur Option „Berechnung jetzt durchführen“ für Extrakte.


