



RegEx steht für „Regular Expression“ und wird in verschiedenen Programmiersprachen verwendet. Es gibt verschiedene Anwendungen von RegEx, zum Beispiel um Daten zu bereinigen, nach bestimmten Mustern zu suchen und diese zu ersetzen oder zu parsen. In Alteryx ist RegEx unter der Werkzeuggruppe „Parse“ zu finden. Es gibt vier Ausgabemethoden, die Alteryx innerhalb des RegEx-Werkzeugs verwendet: parsen, ersetzen, tokenisieren und abgleichen. Dieser Beitrag führt Sie anhand eines einfachen Beispiels durch jede dieser Methoden.
- Parsen
Parse wird verwendet, um Werte in einer Spalte in eine neue Spalte oder mehrere Spalten zu extrahieren. Im folgenden Beispiel habe ich die Telefonnummer in zwei separate Spalten aufgeteilt: Die Vorwahl ist der erste Teil der Nummer, der durch ein Leerzeichen von der Ortsvorwahl getrennt ist, oder in runde Klammern gesetzt wird. Der gesamte Ausdruck der Telefonnummer wird in das Feld „Regulärer Ausdruck“ geschrieben, in dem die beiden neuen Ausgabefelder jeweils innerhalb der runden Klammern definiert sind.
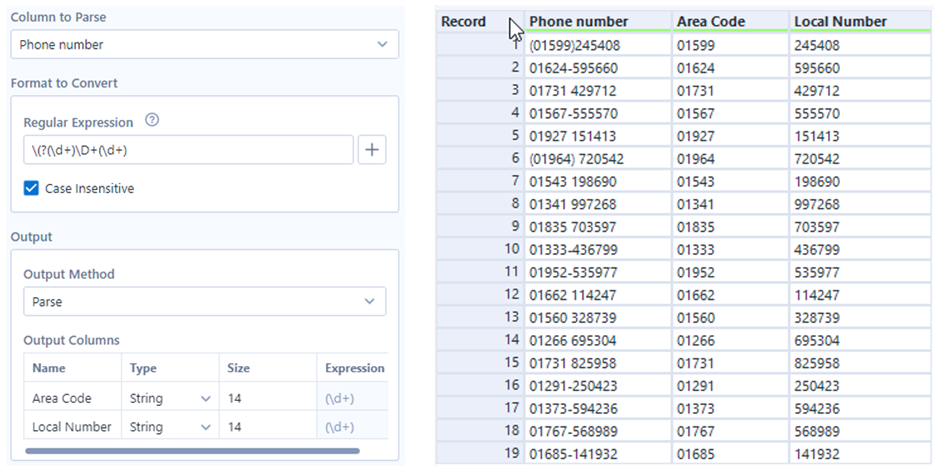
- Ersetzen
Ersetzen wird verwendet, um einen Wert in einer Spalte oder einen Teil davon durch den definierten Ersetzungstext zu ersetzen. Schauen Sie sich das ID-Feld an, es ist als Geschlecht-Nachname-„nm „ID-Nummer formatiert. Nun wollen wir den gesamten Teil Geschlecht-Nachname-„nm“ nur durch den Nachnamen ersetzen, so dass wir am Ende Nachname-ID Nummer haben. Im Feld für reguläre Ausdrücke steht der gesamte Text, der ersetzt werden soll. Ich möchte den Nachnamen herausnehmen, also gruppiere ich ihn mit runden Klammern.
Da es nur eine Gruppe gibt, ist es die Gruppe 1. Im Feld Ersetzungstext habe ich Alteryx angewiesen, die Informationen der Gruppe 1 zu übernehmen, indem ich $1 eintippe.
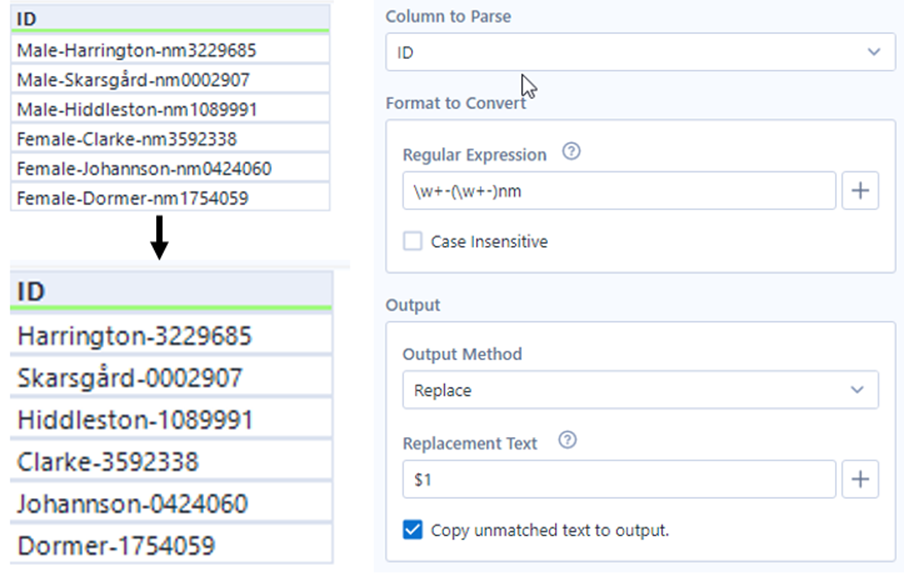
3. Tokenize
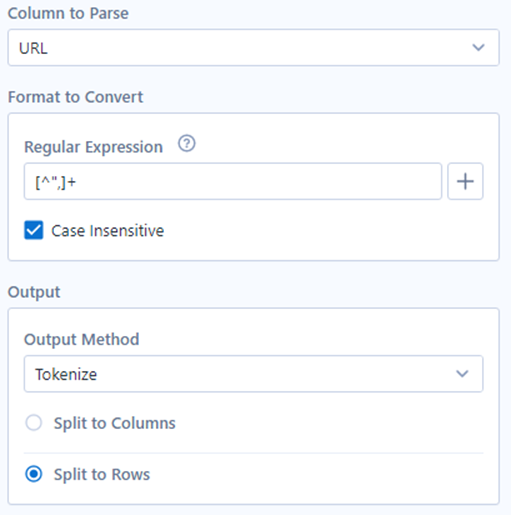
Tokenize splittet eine Spalte in mehrere Spalten oder Zeilen. Die Funktion ähnelt dem Tool „Text in Spalte“, bietet dem Benutzer jedoch mehr Flexibilität durch die Verwendung von RegEx. Betrachten wir den langen Text, der URLs enthält, wie unten gezeigt.

Was wir jetzt wollen, ist, dass jede URL in einer Zeile steht. Achten Sie darauf, dass Sie in der Ausgabemethode das Kästchen „Split to Rows“ aktivieren. Die URLs stehen innerhalb der Anführungszeichen (“ „) und sind durch ein Komma (,) getrennt, so dass wir im regulären Ausdruck alles in der Zeichenkette außer den Anführungszeichen und Kommas verwenden.
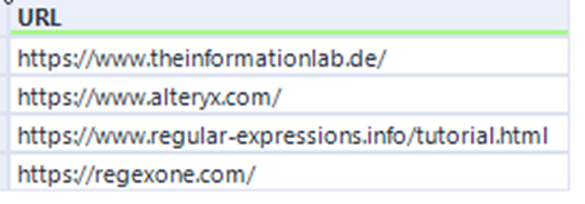
TDie URLs werden wie folgt in Zeilen extrahiert:
- Übereinstimmung
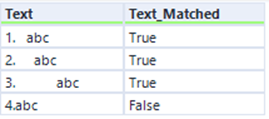
Match gibt als Ergebnis einen booleschen Wert zurück, ob der gesamte Ausdruck mit dem Wert übereinstimmt oder nicht. Diese Ausgabemethode ist recht einfach zu verstehen. Die ersten drei Zeilen in der linken Spalte ergeben „True“ für den Ausdruck:
\d\.\s+abc.
Die vierte Zeile gibt jedoch „Falsch“ zurück, da der Text ein oder mehrere Leerzeichen (\s+) enthalten soll.
Der knifflige Teil dabei ist, den genauen Ausdruck zu schreiben, um nur das benötigte Ergebnis zu erhalten und die anderen zu überspringen.
Der Spaß kann beginnen
Klingt das gut für Sie? Wenn Sie noch mehr Spaß mit RegEx haben wollen, besuchen Sie https://regexone.com/ und machen Sie einige Übungen, die von den Grundlagen bis zu den fortgeschrittenen Stufen reichen. Wenn Sie einen Ausdruck testen möchten, bevor Sie ihn in Alteryx ausführen, gibt es mehrere Websites, auf denen Sie Ihre Texte eingeben und den Ausdruck ausprobieren können, um zu sehen, wie er passt, z. B. https://regexr.com/, https://regex101.com/.
Viel Vergnügen!


